My posts and research about agent reliability focus on software development, because that is my professional domain. Some challenged me with a question: this solves your problems, but does it generalize?
Fair question.
To test, I chose medical imaging. It has existing image processing pipelines with well-understood metrics, reference models, and public datasets. So I followed the pattern: 11 deterministic gates in pure Python, calibrated them on the reference, and wove all this into an orchestrator.
I ran the pipeline unchanged across three different models (Bosma22b, MONAI, and TotalSegmentator) on 1,500 images from the reference dataset.
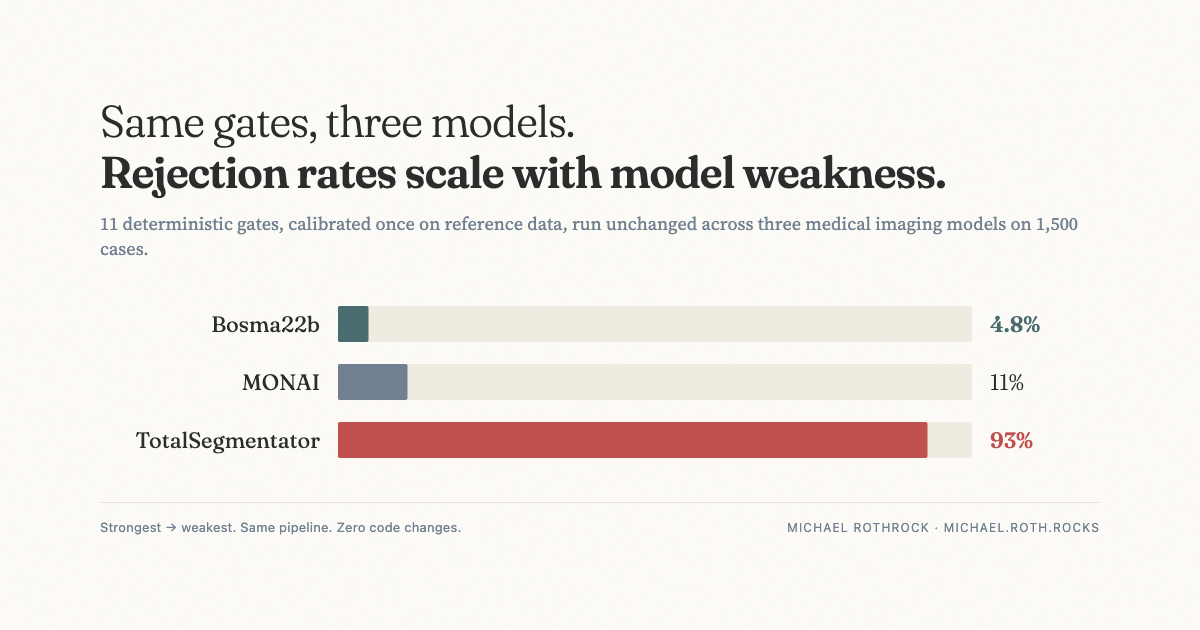
Same gates, same thresholds, zero code changes. The gates caught failures proportional to model weakness: 6.3%, 11%, and 93% (a clear bad fit for the domain). And gates at different pipeline stages caught almost entirely different failures. 2 out of 143 rejections overlapped on the strongest model.
That last point is the one I keep coming back to. With a strong model, almost nothing in the system was redundant. The volume gate, the centroid gate, the boundary gate, the smoothness gate — each was earning its place by catching something the others missed. With a weak model, the same gates caught the same failures over and over, because the model was failing in every dimension at once.
So the gates are doing two jobs at the same time. They reject bad artifacts. And, in aggregate, they tell you what kind of failure the model is producing. Narrow and specific, or broad and global.
The Trust Topology idea generalizes. It's not about software or medicine. It's about checking artifacts at stage boundaries. The gates don't care what domain they're in. They care about the structure of the pipeline.
Full data and methodology are in the paper on Zenodo: Interpretable Cross-Stage Quality Control for AI Medical Imaging Pipelines.
The framework behind this: Trust Topology →